Das semantische Web
Einleitung
In der Ausgabe des Scientific American Magazine vom Mai 2001 haben Tim Berners-Lee, James Hendler und Ora Lassila ihre Idee des semantischen Web beschrieben: The Semantic Web - A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities. Manchmal wird das semantische Web auch als "Web 3.0" bezeichnet. Die W3 Consortium (W3C) Data Activity verwendet seit 2013 den Begriff "Web of Data".

Vom "Web of Documents" zum "Web of Data"
Der Inhalt einer Webseite, den der Browser auf dem Bildschirm darstellt, ist in einem Text-Dokument beschrieben. Zur Beschreibung dient die Auszeichnungssprache HTML (HyperText Markup Language). Die HTML-Elemente zeichnen Überschriften (z.B. <h1>, <h2>), Paragraphen (<p>), Aufzählungen (z.B. <ul>), usw. aus. Sie können auch Bilddateien (<img>) oder Audio- und Videodateien (<audio> bzw. <video>) bezeichnen und auf weitere Webseiten verweisen (<a>). Der Browser interpretiert die HTML-Elemente und stellt den Inhalt der Webseite auf dem Bildschirm entsprechend dar. Das von Tim Berners-Lee et al. 2001 skizzierte semantische Web umfasste zwei wesentliche neue Ideen:
- Die Inhalte von Webseiten werden mit semantischen Auszeichnungen so ergänzt, dass deren Bedeutung nicht nur von Menschen, sondern auch von Programmen erkannt werden kann.
- Die Suche nach Inhalten im Web erfolgt mit Programmen (Software-Agenten), die über die Analyse der semantischen Ergänzungen auf den Webseiten erkennen können, welche Inhalte auf die Suchanfrage passende Antworten liefern.
Beispiel: Wir können in der nebenstehenden Abbildung einer Webseite sofort die Titel und die Namen der Autoren von zwei Büchern erkennen.

Ein Computerprogramm kann das aus dem HTML-Text dieser Webseite aber nicht erkennen.
<html> <head> <meta charset="utf-8"/> <link rel="stylesheet" href="semweb.css"/> <title>"Neuerwerbungen</title> </head> <body> <div class="description"> <h3>Otto F. Walter: Zeit des Fasans</h3> <p>Rowohlt, 2002</p> </div> <div class="description"> <h3>Walter F. Otto: Dionysos</h3> <p>Indiana University Press, 1995</p> </div> </body> </html>
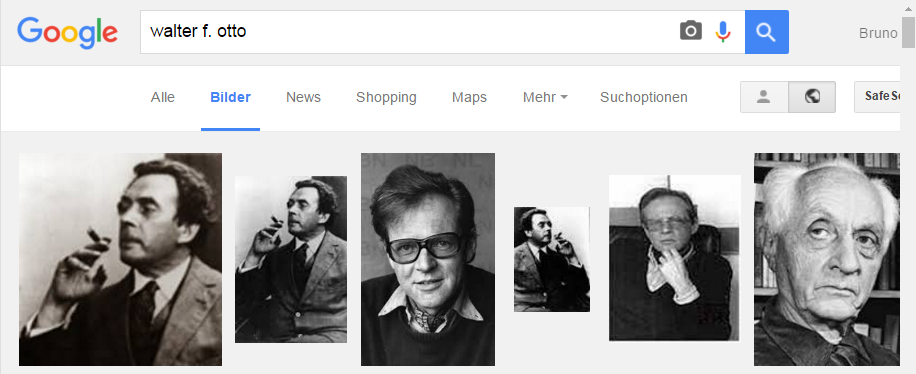
Deshalb liefert die Suche nach "Walter F. Otto" (z.B. bei Google, Bing, Yandex, Yahoo, Swisscows, usw.) auch Bilder von "Otto F. Walter" und sogar Bilder von ganz anderen Personen und "Dingen".
Die semantische Auszeichnung der Inhalte von Webseiten macht deren Bedeutung auch für Computerprogramme erkennbar. Dazu braucht es ein standardisiertes kontrolliertes Vokabular. Mittlerweile hat sich dafür das Vokabular schema.org etabliert.
Ausserdem ist eine definierte Syntax nötig, um die Inhalte entsprechend zu kennzeichnen, z.B. Mikrodaten.
Die semantische Auszeichnung von "Otto F. Walter" mit Mikrodaten in der obigen Beispiel-Webseite könnte folgendermassen aussehen:
<div class="description"> <h3> <span itemscope itemtype="http://schema.org/Person"> <span itemprop="givenName">Otto</span> <span itemprop="additionalName">F.</span> <span itemprop="familyName">Walter</span> <meta itemprop="gender" content="male" /> </span>: Zeit des Fasans </h3> <p>Rowohlt, 2002</p> </div>
In der gleichen Weise könnten auch der Buchtitel und der Verlag mit Mikrodaten ausgezeichnet werden, damit Computerprogramme (z.B. die Suchmaschinen) die Bedeutung dieser Angaben erkennen könnten.
Was ein Computerprogramm erkennen kann, zeigt die Analyse des mit Mikrodaten ausgezeichneten HTML-Textes mit dem Online Service Structured Data Linter:

Mit einem Konverter für Mikrodaten kann die Datenstruktur auch in RDF/XML umgewandelt werden, z.B. mit dem Online RDF Translator:
<?xml version="1.0" encoding="UTF-8"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfa="http://www.w3.org/ns/rdfa#" xmlns:schema="http://schema.org/"> <rdf:Description rdf:about=""> <rdfa:usesVocabulary rdf:resource="http://schema.org/"/> </rdf:Description> <rdf:Description rdf:nodeID="N113c91e2e7ce4999a386e8501cbf4e9b"> <schema:givenName>Otto</schema:givenName> <schema:gender>male</schema:gender> <rdf:type rdf:resource="http://schema.org/Person"/> <schema:familyName>Walter</schema:familyName> <schema:additionalName>F.</schema:additionalName> </rdf:Description> </rdf:RDF>
Eine weitere Syntax zur Beschreibung der Bedeutung der Inhalte von Webseiten (bzw. ganz allgemein von Linked Data) bietet JSON-LD, eine JSON-basierte Serialisierung von Linked Data. Mit JSON-LD beschriebene Daten lassen sich ebenfalls in HTML-Texte integrieren. Die Beschreibung ist aber im Gegensatz zu der Syntax von Mikrodaten kompakter und lässt sich als separater Block in den HTML-Text einfügen. Unser Beispiel im JSON-LD-Format (ebenfalls mit dem Online RDF Translator aus den Mikrodaten generiert):
{ "@context": { "gr": "http://purl.org/goodrelations/v1#", "qb": "http://purl.org/linked-data/cube#", "rdf": "http://www.w3.org/1999/02/22-rdf-syntax-ns#", "rdfs": "http://www.w3.org/2000/01/rdf-schema#", "schema": "http://schema.org/", "skos": "http://www.w3.org/2004/02/skos/core#", "xsd": "http://www.w3.org/2001/XMLSchema#" }, "@graph": [ { "@id": "_:N21175276fb244ca4997989436549144c", "@type": "schema:Person", "schema:additionalName": "F.", "schema:familyName": "Walter", "schema:gender": "male", "schema:givenName": "Otto" }, { "@id": "", "rdfa:usesVocabulary": { "@id": "schema:" } } ] }