Strukturierte Beschreibung von Daten mit RDF
Einleitung
Um mit Computerprogrammen digitale Inhalte erschliessen zu können, müssen sie strukturiert (maschinenlesbar) sein.
Einen Ansatz dazu bietet die eXtensible Markup Language XML. Mit XML können Auszeichnungssprachen mit selbst gewählten Bezeichnern (tags) entwickelt werden. Eine derartige Auszeichnungssprache ermöglicht die Beschreibung von hierarchischen ("baumartigen") Datenstrukturen und damit den Austausch von entsprechenden Datensätzen zwischen unterschiedlichen Computersystemen.
Das Problem, das XML lösen hilft
Viele Datenstrukturen bilden eine Hierarchie ab, beispielsweise die Metadaten für ein Buch:
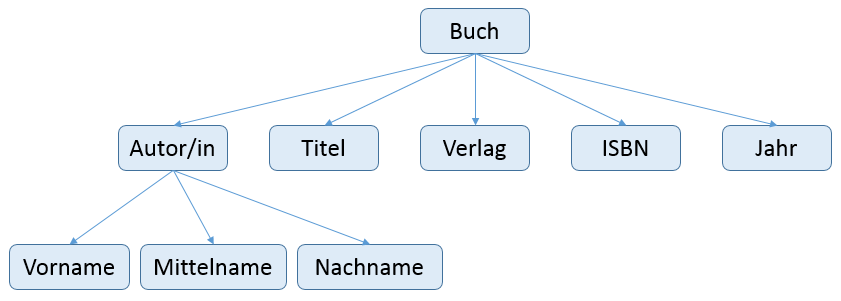
Der Computer versteht eine solche Grafik allerdings nicht. Wir benötigen eine Sprache, mit der wir baumartige Datenstrukturen in Textform beschreiben können. Die eXtensible Markup Language XML ist eine derartige Beschreibungssprache. Sie heisst „extensible“, weil sie zulässt, dass wir (unter Beachtung der Syntaxregeln) zur Beschreibung einer Datenstruktur eigene „Wörter“ verwenden können (im Gegensatz zur Hypertext Markup Language HTML, bei der die „Wörter“ (Elementnamen, tags) festgelegt sind).
Die eXtensible Markup Language XML
XML ist das Akronym (das Kürzel) für eXtensible Markup Language. Mittels XML lassen sich (baumartig) strukturierte Daten in einer maschinenlesbaren Form abspeichern. Ein einfaches Beispiel soll dieses Konzept veranschaulichen: Die Struktur einer Adresse.
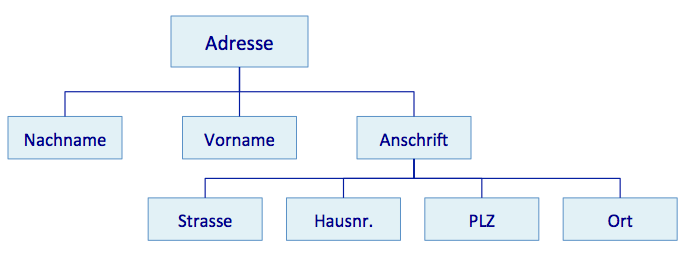
Die Beschreibung einer Adresse in XML könnte nun folgendermassen aussehen:
<?xml version="1.0" encoding="UTF-8"?> <adresse> <name> <nachname>Bruchmüller</nachname> <vorname>Sebastian</vorname> </name> <anschrift> <strasse>Oberstrasse</strasse> <hausnr>56</hausnr> <plz>9000</plz> <ort>St.Gallen</ort> </anschrift> </adresse>
XML-Dokumente werden üblicherweise in Textdateien mit der Endung .xml gespeichert. Die Beispiel-adresse könnte in einer Datei mit dem Dateinamen adresse.xml gespeichert werden.
Wie müssen wir dieses XML-Dokument interpretieren?
<?xml version="1.0" encoding="UTF-8"?> stellt die XML-Deklaration dar und verweist auf die zugrunde liegende Version von XML. Das Encoding (im Beispiel UTF-8) legt fest, wie die Zeichen des Textes im Computer intern gespeichert werden. Dies ist nötig, weil der Inhalt von XML-Dokumenten (aber nicht die Elementnamen!) Zeichen aus beliebigen Alphabeten (deutsch: äöü, kyrillisch: фрьтъ, chinesisch: 普通话, usw.) enthalten kann.
Mit <vorname>Sebastian</vorname> wird dem Element <vorname> der Wert Sebastian zugeordnet. Das Element <vorname> besteht aus drei Teilen: der Startkennzeichnung (start tag) <vorname>, dem eigentlichen Wert Sebastian und der Endkennzeichnung (end tag) </vorname>.
Die in der grafischen Darstellung deutlich sichtbare hierarchische Struktur einer Adresse spiegelt sich auch im XML-Dokument wieder: Die einzelnen Teile der Adresse sind in das Element <adresse> eingeschlossen. Durch entsprechendes Einrücken hebt man die hierarchische Struktur normalerweise auch im XML-Dokument hervor. Im Beispiel steht
Syntaxregeln
| Regel 1: | Ein XML-Dokument beginnt mit der XML-Deklaration Beispiel: <?xml version="1.0" encoding="UTF-8"?> |
| Regel 2: | Ein XML-Element umfasst ein Start-Tag und ein Endtag Beispiel: <vorname></vorname> |
| Regel 3: | Ein XML-Element enthält einen Wert oder weitere XML-Elemente Beispiel: <anschrift></vorname> <strasse>Oberstrasse <hausnr>56</hausnr> <plz>9000</plz> <ort>St.Gallen</ort> </anschrift> |
| Regel 4: | Ein XML-Element kann Attribute haben Beispiel: <name nachname="Bruchmüller" vorname="Sebastian"></name> |
| Regel 5: | XML-Elemente müssen korrekt verschachtelt sein Beispiel: <name nachname="Bruchmüller" vorname="Sebastian"></name> |
| Regel 6: | XML-Elemente ohne Wert kann man abgekürzt schreiben Beispiel: <name nachname="Bruchmüller vorname="Sebastian" /> |
Wohlgeformtheit und Validität
Werden von einem XML-Dokument alle Syntax-Regeln eingehalten, dann ist es wohlgeformt (well-formed).
Die Baumstruktur kann mit Hilfe eines XML-Schemas präzise festgelegt werden. Dazu gehören die Festlegung der Bezeichner für die Elemente, die Reihenfolge der Elemente, die Anzahl der möglichen Wiederholungen eines Elements, der gültige Wertebereich eines Elements, usw. Wenn ein wohlgeformtes XML-Dokument auch einem vorgegebenen Schema genügt, nennt man es valide (valid).
Die Wohlgeformtheit und Validität eines XML-Dokuments können mit einem XML-Validator überprüft werden, beispielsweise mit dem Online XML Schema Validator.
Hierarchisch strukturierte Daten spielen in der Praxis immer noch eine bedeutende Rolle. Mittlerweile sind aber die Beziehungen zwischen den Datensätzen immer wichtiger geworden. Dieser Entwicklung tragen die relationalen Datenbanken Rechnung, in denen Tabellen mit den Beschreibungen einzelner Entitäten ("Dinge", "resources") verknüpft werden können.
Das Ziel wäre nun, die allgemein interessierenden Daten aus den Datenbanken ("Silos") zu "befreien" und im Web der Öffentlichkeit zur Nutzung zur Verfügung zu stellen. Dieser Schritt würde zu einem Netz von miteinander verknüpften Datensätzen führen:
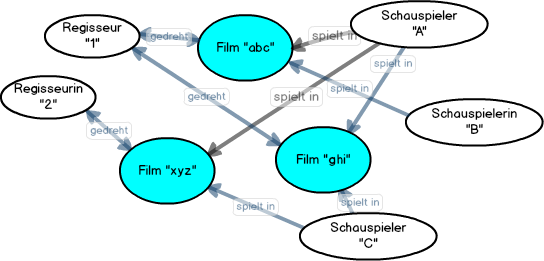
Das Resource Description Framework RDF
Das Resource Description Framework bietet ein Modell zur Beschreibung von "Dingen" (resources). Die Beschreibung der "Dinge" (z.B. RegisseurInnen, SchauspielerInnen, Filme) erfolgt mit dreigliedrigen Ausdrücken (Triples). Ein Triple umfasst das Subjekt (S), das Prädikat (p) und das Objekt (O).

Ein Film, den Orlando vorführen will, könnte mit Triples beispielsweise folgendermassen beschrieben werden:
"Der Film" "hat Titel" "The Great Gatsby" "Der Film" "hat Sprache" "Englisch" "Der Film" "hat als Regisseur" "Jack Clayton" "Der Film" "wurde veröffentlicht im Jahr" "1974"
Damit die Beschreibung maschinenlesbar wird, müssen die Bezeichner ("Der Film", "hat Titel", usw.) einem kontrollierten Vokabular entnommen werden. Dazu eignet sich beispielsweise das Vokabular schema.org.
"http://schema.org/Movie" "http://schema.org/name" "The Great Gatsby" "http://schema.org/Movie" "http://schema.org/inLanguage" "Englisch" "http://schema.org/Movie" "http://schema.org/director" "Jack Clayton" "http://schema.org/Movie" "http://schema.org/copyrightYear" "1974"
Das Subjekt und die Objekte können als Knoten eines Netzes (eines Graphen) und die Prädikate als mit Namen versehene Verbindungen (Kanten) zwischen den Knoten aufgefasst werden. In unserem Beispiel repräsentieren die verbundenen Knoten Werte von Merkmalen des Film-Knotens.
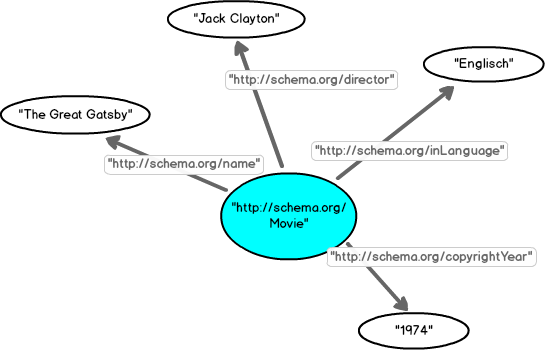
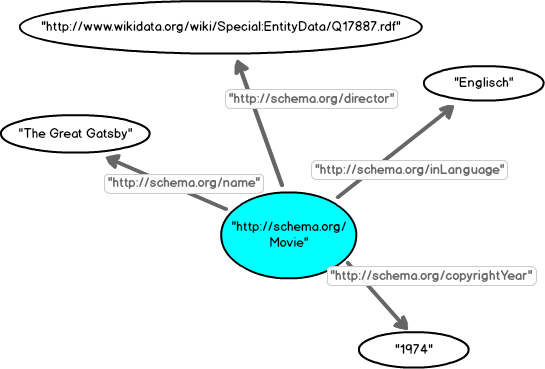
Besonders interessant sind Objekte, die nicht als Zeichenfolge (literal), sondern als Verweis auf ein anderes "Ding" beschrieben werden. Dadurch erweitert sich das Netz (der Graph) zu einem Netz, bei dem die Knoten Merkmalswerte von Subjekten oder wieder Subjekte sein können. Damit ist RDF die Beschreibungs-Grundlage für Linked Data. In unserem Beispiel können wir den Namen des Regisseurs ("Jack Clayton") durch den Verweis auf einen Datensatz mit Angaben zur Person Jack Clayton ersetzen. Einen solchen Datensatz finden wir auf Wikidata.
Die Syntax von RDF
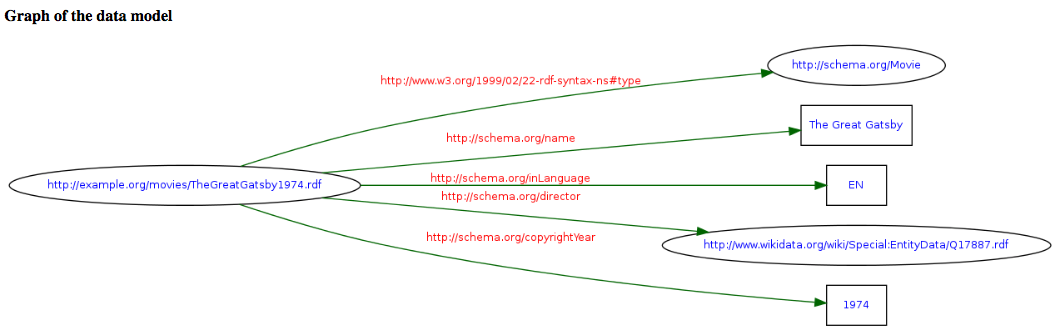
Um den Graph für ein "Ding" (die Triples) in Textform maschinenlesbar zu formulieren, ist eine passende Syntax notwendig. XML eignet sich dafür: RDF/XML. Der folgende Text beschreibt unser Beispiel in RDF/XML.
<?xml version="1.0" encoding="UTF-8"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:schema="http://schema.org/"> <rdf:Description rdf:about="http://example.org/movies/TheGreatGatsby1974.rdf"> <rdf:type rdf:resource="http://schema.org/Movie"/> <schema:name>The Great Gatsby</schema:name> <schema:inLanguage>EN</schema:inLanguage> <schema:director rdf:resource="http://www.wikidata.org/wiki/Special:EntityData/Q17887.rdf" /> <schema:copyrightYear>1974</schema:copyrightYear> </rdf:Description> </rdf:RDF>
Die "Dinge" müssen dazu mit einem Unified Resource Identifier (URI) eindeutig gekennzeichnet sein. Für die Veröffentlichung im Web eignen sich HTTP-URIs, in unserem Beispiel "http://example.org/movies/TheGreatGatsby1974.rdf". Ausserdem müssen die XML Namensräume (namespaces, kontrollierte Vokabulare), aus denen die verwendeten Bezeichner stammen, aufgeführt werden, in unserem Beispiel "xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" und "xmlns:schema="http://schema.org/".
Die Korrektheit der Beschreibung in RDF/XML kann mit einem RDF-Validator geprüft werden, z.B. mit dem W3C RDF Validation Service. Als Ergebnis werden die Triples aufgelistet und nach Bedarf ein entsprechender Graph dargestellt: